
绘制饼形图
import matplotlib.pyplot as plt import numpy as np plt.subplot(1,1,1) labels = ["Frogs", "Hogs", "Dogs", "Logs"] # 定义标签 ...
import matplotlib.pyplot as plt import numpy as np plt.subplot(1,1,1) labels = ["Frogs", "Hogs", "Dogs", "Logs"] # 定义标签 ...

sns画法 import pandas as pd import matplotlib.pyplot as plt import seaborn as sns income = pd.read_csv('Salary_Data.csv') ...

代码如下: import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv('../datasets/tips.csv') plt.boxplot(x = df['t...
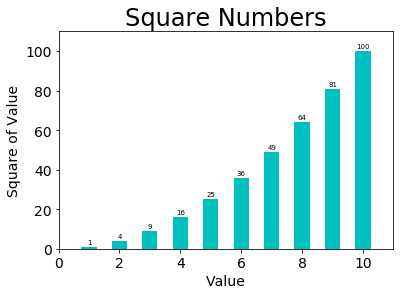
1、plt.text()函数 #创建带数字标签的直方图 numbers = list(range(1,11)) #np.array()将列表转换为存储单一数据类型的多维数组 x = np.arange(1,11) y = x**2 plt....
Pandas修改列名总是需要生成一个新列名序列,然后再将列名指向新列名序列。 生成一个表 data = pd.DataFrame({'A':[1,2,3,4,2],"D":[4,5,6,7,5],'C':[7,8,9,3,8]}) 这里要把...

重复数据就是同样记录有多条,一般做删除处理。 首先生成一个包含重复数据的表 data = pd.DataFrame({'A':[1,2,3,4,2,5,4],"B":[4,5,6,7,5,8,7],'C':[7,8,9,3,8,9,3]})...

首先生成一个带有缺失值的表 data = pd.DataFrame({'A':[1,2,None],"B":[4,None,6],'C':[None,8,9]}) 缺失值查看 使用isna()或Isnull()函数,会有在有缺失的位置上显示...
列表的合并 列表的合并就是将现有的两个list合并在一起,主要有两种实现方式,一种是用+操作符,它和字符串的连接一致;另外一种用的是extend()函数。 a = ["a","b","c"] b = [1,2,3] a + b a.exte...

